General Information on Objects
Understanding how Nutanix Objects works provides a useful context for any sizing. To read about the architecture check out the Objects Tech Note: https://portal.nutanix.com/page/documents/solutions/details?targetId=TN-2106-Nutanix-Objects:TN-2106-Nutanix-Objects
To understand the current maximums visit: https://portal.nutanix.com/page/documents/configuration-maximum/list?software=Nutanix%20Objects
Nutanix Objects falls under Nutanix Unified Storage (NUS) licensing. For an overview of NUS licensing visit: https://www.nutanix.com/products/cloud-platform/software-options#nus
Performance vs. Capacity Workloads
In the past object storage solutions were only concerned with capacity; performance was barely a consideration. However, modern workloads such as AI/ML and data analytics leverage S3 compatible storage, and these very often have significant performance demands. Nutanix Objects has been internally benchmarked with both hybrid and all flash systems (see https://portal.nutanix.com/page/documents/solutions/details?targetId=TN-2098-Nutanix-Objects-Performance-INTERNAL-ONLY:TN-2098-Nutanix-Objects-Performance-INTERNAL-ONLY) and as a result we have a good understanding into Objects’ performance capabilities with a variety of workload profiles. Extrapolations can reliably be taken from these results to model performance scaling, since Objects I/O performance scales linearly. Importantly, the empirical data gleaned from the benchmark testing is leveraged by Sizer to determine the minimum number of Objects workers – and therefore nodes (Objects enforces 1 worker per node per object store for HA reasons) – needed to deliver a certain level of performance.
It should also be noted that there are factors outside the object store, such as network speed and number of client connections, that play a significant role in achieving the best possible performance from Nutanix Objects. Regarding the number of client connections, it should be noted that each node/worker needs 60-75 concurrent client connections driving I/O for maximum performance potential to be realized.
More commonly, node count will be driven by capacity requirements. Even in these cases however, the minimum Objects worker count needed for the required performance should still be noted, especially in mixed deployments (discussed further below).
Configurations
While there is no difference in NUS licensing between dedicated deployments (the AOS cluster is dedicated to NUS) and mixed deployments (NUS resides on the same cluster as application VMs), sizing considerations in each scenario vary to a degree. These are discussed below.
Information about hardware models suitable for Objects (and Files) can be found at: https://www.nutanix.com/products/hardware-platforms/specsheet?platformProvider=Nutanix&useCase=Files%20and%20Objects. The link points to Nutanix NX models, but you can easily change the hardware vendor as required. At the time of writing, HPE provides the node with the highest storage density (DX4120-G11). Make sure ‘Files and Objects’ is selected as the use case.
Worker count and HDD spindle count (or SSD count if All Flash)
In scenarios where a certain level of performance must be met, Sizer will look at the number of workers needed and the number of HDDs (or SSDs in the case of all flash) needed to deliver the throughput entered*. A high performance worker on an all flash node can, in most scenarios, deliver substantially more throughput than a standard worker on a hybrid node.
Disk-wise, in RF2 configs Sizer assumes a single SATA HDD can deliver reads:100MB/s and writes:50MB/s. Sizer assumes a single SSD can deliver reads:500MB/s and writes:250MB/s. So for example, a hybrid node with 10*HDDs can deliver 1GB/s for a workload consisting entirely of reads, or 500MB/s for a workload consisting entirely of writes. If RF3 or FT1n/2d is selected the write throughput figure is increased by 50% to account for the additional disk write IO. Note that FT1n/2d is strongly recommended for storage dense configs.
*For performance sensitive sizings please do not just accept the default values in the performance profile section (“Profile Info” box in the top right of the Workload page). The default values are purely arbitrary. You must determine the actual average object size, R/W (get/put) split and throughput that the customer needs to achieve and enter that customer-specific data into the Profile Info section.
For an Objects dedicated configuration (hybrid)
Objects is supported on all models and platforms that can run AOS (NCI). However, if you’re sizing for a dedicated hybrid Objects cluster with 100TiB or above, we recommend the HPE DX4120-G11, NX-8155-G9 or equivalent for the best performance. Such models are ideal due to their high HDD spindle count (as discussed in the previous section), though any model will work as long as it matches the minimum configurations listed below.
- CPU: dual-socket 12-core CPU (minimum) for hybrid configs with 4 or more HDDs
- Dual-socket 10-core CPU is acceptable for hybrid configs in use cases that do not require fast performance
- Memory: 128GB per node (minimum)
- Disk:
- Avoid hybrid configurations that have only 2 HDDs per node.
- For hybrid configurations that need to deliver good throughput, systems with 10+ HDDs are highly recommended. On an NX8155 for example go for 2*SSD + 10*HDD rather than 4*SSD + 8*HDD. This is further explained in the below section Why 10+ HDDs in a dedicated hybrid config?
- If a system with 10 or more HDDs is not available, configure the system with the highest number of HDDs possible.
- Erasure Coding: inline enabled (set by default during deployment)
- Note inline EC has a 10-15% impact on write performance (accounted for if you choose “inline EC” in Sizer)
- FT choice: choosing between RF3, FT1N/2D and RF3 has an impact on the system’s deliverable write throughput (see previous section “Worker count and HDD spindle count (or SSD count if All Flash)”)
- Network: dual 25GbE generally recommended (but check calculation in “Network” section)
NOTE: In Sizer to force a hybrid cluster output make sure “Hybrid” is selected under “Worker Node”. Sizer does not automatically choose between hybrid or all-flash for you.
Licensing: NUS Starter covers any Objects deployment on a hybrid system (whether shared or dedicated).
Why 10+ HDDs in a dedicated hybrid config?
In the majority of today’s use cases objects tend to be large (>1.5MiB), meaning they manifest as sequential I/O on the Nutanix cluster. In response to this, Objects architecture is tuned to take full advantage of the HDD tier. If there are HDDs in a node, Objects will automatically write sequential data directly to them, while leveraging the SSDs purely for metadata (if there are any objects under 1.5MB these will land in the SSD tier).
There are 3 reasons for this;
- Solid sequential I/O performance can be achieved with HDDs, assuming there are enough of them
- Objects deployments can be up to petabytes in size. At that sort of scale, cache or SSD hits are unlikely, so using SSDs in hopes of achieving accelerated performance through caching would provide little return on the additional costs. To keep the solution cost-effective, Objects minimizes SSD requirements by using SSDs for metadata, and only using for data if required.
- Since we recommend a dual-socket 12-core CPU configuration, fewer SSDs also helps to avoid system work that would otherwise be incurred by having to frequently move data between tiers – the result is less stress on the reduced CPU count.
If, however, the workload is made up of mostly small objects, all-flash systems are significantly better at catering for the resulting random I/O, particularly if the workload is performance intensive.
For an Objects dedicated configuration (all-flash)
If all-flash is the preference, any system with 3 or more SSD/NVMe devices is generally fine, although the calculation described earlier must be performed based on actual throughput requirements (Sizer does this). If the all-flash nodes must also be storage dense we recommend the NX-8150-G9. From a compute standpoint, all-flash Objects clusters should have a minimum of:
- CPU: dual-socket 20-core CPU (minimum) for all-flash configs – importantly, this allows the “Performance Config” to be selected at deployment
- Memory: 128GB per node (minimum)
- Disk: For all flash configurations, systems with 3 SSDs/NVMes (or more) are recommended.
- Erasure Coding: inline enabled (set by default during deployment)
- Note inline EC has a 10-15% impact on write performance (accounted for if you choose “inline EC” in Sizer)
- FT choice: choosing between RF3, FT1N/2D and RF3 has an impact on the system’s deliverable write throughput (see previous section “Worker count and HDD spindle count (or SSD count if All Flash)”)
- Network: quad 25GbE, dual 40GbE or higher generally recommended, and for very high performance requirements dual 100GbE will be needed (check calculation in “Network” section)
NOTE: In Sizer to force an all-flash cluster output make sure “All Flash” is selected under “Worker Node”. Sizer does not automatically choose between hybrid or all-flash for you.
Licensing: NUS Pro covers any Objects deployment on an all flash system (whether shared or dedicated).
For a mixed configuration (Objects coexisting with User VMs)
Objects is supported on any model and any platform as long as it matches the minimum configurations listed below.
- CPU: at least 12 vCPUs are available per node
- All node types with dual-socket CPUs are supported and preferred, though single CPUs with at least 24 cores are also supported
- Memory: at least 36GB available to Objects per node
- Disk: avoid hybrid configurations with only 2 HDDs per node and bear in mind that more HDD spindles means better performance.
- Erasure Coding: Inline enabled (set by default during deployment)
- Note inline EC has a 10-15% impact on write performance (accounted for if you choose “inline EC” in Sizer)
- FT choice: choosing between RF3, FT1N/2D and RF3 has an impact on the system’s deliverable write throughput (see previous section “Worker count and HDD spindle count (or SSD count if All Flash)”)
- Erasure Coding: Inline enabled (set by default during deployment)
- Network: dual 25GbE recommended (but check calculation in “Network” section)
Both the NUS Starter and Pro licenses allow one User VM (UVM) per node. If taking advantage of this, ensure that there are enough CPU cores and memory on each node to cater for both an Objects worker and the UVM – and potentially also a Prism Central (PC) VM, unless PC will be located on a different cluster. It’s important to understand that Nutanix Objects cannot be deployed without there being a Prism Central present somewhere in the environment.
Network
This section provides information on working out the network bandwidth (NIC speed and quantity) needed per node, given the customer’s throughput requirement and the number of load balancers in the deployment. Conversely, it can be used to work out how many load balancers are needed, particularly if the customer is limited to a particular speed of network. At the end of this section is a link to a spreadsheet that helps you perform these calculations.
Note that Sizer does not perform these calculations. Sizer will statically configure all-flash Object nodes with 4 x 25GbE ports (two dual port cards). However, that might not be enough so it’s important that you do the performance calculations below and, if necessary, manually increase the NIC speed and/or quantity in Sizer as needed.
1. Firstly it’s important to be aware that for each put (write) request received by Objects there is 4x network amplification. The write path is as follows:
- Client > Load Balancer (1) > Worker (2) > CVM (3) > RF write to another CVM (4)
If RF3 or 1N2D is selected this increases to 5x network amplification
For each get (read) request received there is 3x amplification. The read path is as follows:
- CVM > Worker (1) > Load Balancer (2) > Client (3)
If EC is selected (EC is default if there are enough nodes) read amplification could, for many gets, increase to 4x if parts of the EC strip need to be read from other CVMs.
So the total network bandwidth needed for the object store is determined by the customer’s requested throughput multiplied by these factors in the correct proportions (R/W). The resulting overall bandwidth requirement is then spread across the load balancers – a relatively even distribution is assumed.
2. Take whatever % of the customer’s throughput is write IO (puts) – this is typically expressed in MB/s or GB/s – and multiply by 4 (or 5 – see above) to account for the write amplification. Next, take whatever % of the customer’s throughput is read IO (gets) and multiply that by 3 (or 4 – see above) to account for the read amplification. Combine the results and you have the overall throughput requirement to/from the cluster.
Example:
Customer requirement:
Throughput = 5 GB/s
% puts = 20
Write throughput = 1 GB/s x 4 (write amplification) = 4 GB/s
Read throughput = 4 GB/s x 3 (read amplification) = 12 GB/s
Total bandwidth to/from object store = 4 GB/s + 12 GB/s = 16 GB/s
3. Divide the overall throughput figure by the number of load balancers you plan to deploy. The result is the amount of network bandwidth needed per physical node.
Example:
4 Load Balancers
16 GB/s / 4 = 4 GB/s per node
4. Map this figure to the real world limits of NICs of varying speeds. These are listed below for your convenience. Note that when 2 links are aggregated using LACP you do not get twice the bandwidth of a single link due to overheads. With 2 links in LACP you can assume ~20% bandwidth loss, with 4 you can assume ~40% loss. Further to that, and before LACP overhead is accounted for, a NIC’s advertised bandwidth is never fully achievable due to general networking overheads (protocol and other real world factors).
| # links in LACP | 1 (no aggregation) | 2 | 4 |
| Achievable GB/s | 1.1 | 1.8 | 2.7 |
Usable bandwidth with 10GbE
| # links in LACP | 1 (no aggregation) | 2 | 4 |
| Achievable GB/s | 2.8 | 4.4 | 6.6 |
Usable bandwidth with 25GbE
| # links in LACP | 1 (no aggregation) | 2 | 4 |
| Achievable GB/s | 4.4 | 7.0 | 10.4 |
Usable bandwidth with 40GbE
| # links in LACP | 1 (no aggregation) | 2 | 4 |
| Achievable GB/s | 10.5 | *12.5 (not 16.8) | *12.5 (not 25.2) |
Usable bandwidth with 100GbE
*At the time of writing OVS, the virtual switch architecture used by AHV/KVM, has a limit of 100Gbps – this means the maximum network throughput a single node can handle is 12.5 GB/s (100/8). The configurations affected by this are 2x and 4x 100GbE links in LACP. There are future plans to lift this limit (roadmap item).
Example:
4 GB/s per node is needed.
Each node needs 2 x 25GbE NICs (in LACP), which can do 4.4GB/s
This spreadsheet may help with the network bandwidth and load balancer calculations.
Sizing Use Cases
Use Case: Backup
Below is a Backup workload in Objects Sizer. In this scenario Nutanix Objects is used as a target to store backups sent from backup clients (i.e. the backup app).
Note that Nutanix Objects should not be located on the same physical cluster as the source data (i.e. the data being backed up).
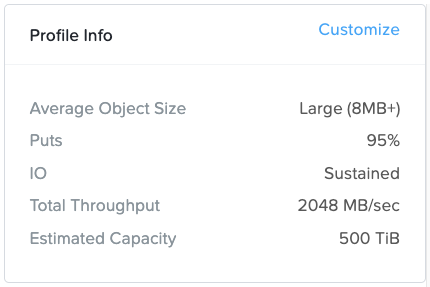
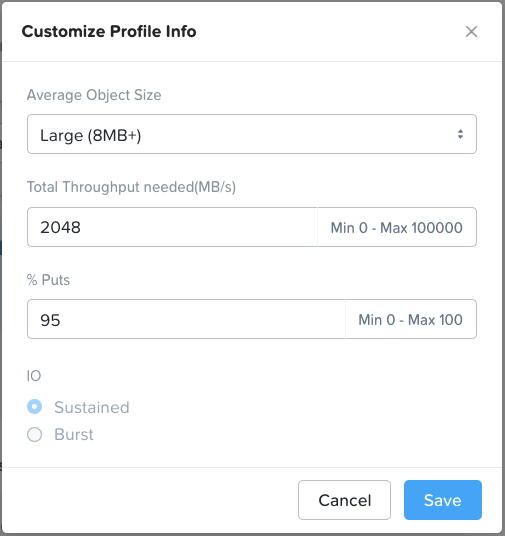
Considerations when sizing a backup workload
- Initial capacity – estimated initial capacity that will be consumed by backups stored on Nutanix Objects.
- Capacity growth – % growth of the backup data per time unit (e.g. years) over an overall specified length of time.
- Be cautious and do not attempt to cater for too long a growth period, otherwise the amount of capacity required due to growth could dwarf the amount of storage required on day one. Specifying a (for example) 10-year growth period undermines our fundamental pay-as-you-grow value. Plus of course growth predictions may not be entirely accurate in any case. 3 years is a typical growth period to size for.
- Do not enable Nutanix deduplication on any Objects workloads.
- Profile Info:
- All values can be customized as required.
- Write (PUT) traffic usually dominates these environments as backups occur more regularly than restores (GETs). Furthermore, when restores do occur they are usually just reading a small subset of the backup.
- That said, more and more customers are becoming increasingly concerned with how fast all their data could be restored in the event of a ransomware attack – so do check this with the customer
- Backups usually result in sequential I/O so the requirement is expressed as MB/s throughput. Veeam is the one exception to this rule – discussed further below.
- Backups usually consist of large objects (with the exception of Veeam – discussed further below)
- “Sustained” only applies to small object (<1.5MB) puts. In a hybrid system, when the hot tier fills up the application I/O must wait while the data is drained from SSD/NVMe to HDD. This is why sustained small object put throughput is slower than burst small object put throughput.
- Replication Factor
- When using nodes with large disks (12TB+) to achieve high storage density it’s recommended you use RF3 or, better still, 1N/2D if there are 100 or more disks in a single fault domain. This provides a higher level of resilience against disk failure. Disk failure is more likely in this scenario for two reasons:
- The more disk hardware you have the greater the risk of a disk failure
- Disks take longer to rebuild because they contain more data, thus the window of vulnerability is extended (to days rather than hours)
- The larger drive capacities also mean there is a greater chance of encountering a latent sector error (LSE) during rebuild
- This drives a real need for protection against dual disk failure – true regardless of whether the disks are HDD or SSD/NVMe.
- 1N/2D coupled with wider EC strip sizes is preferred to RF3 due to it being more storage efficient
- If you wish to stick with RF2, consider using multiple Objects clusters.
- However each cluster will have its own N+1 overhead.
- When using nodes with large disks (12TB+) to achieve high storage density it’s recommended you use RF3 or, better still, 1N/2D if there are 100 or more disks in a single fault domain. This provides a higher level of resilience against disk failure. Disk failure is more likely in this scenario for two reasons:
Special rules for Veeam
Veeam is different from other backup apps in that it does not write large objects. With Veeam the default object size is ~768KB, about a tenth (or less) of the size of objects generated by other backup apps. Therefore, for Veeam opportunities the specialized “Backup – Veeam” use case in Sizer should be selected. Note that small object performance requirements must be expressed in Sizer in requests/sec rather than MB/sec. Therefore some conversion may be required if the customer has provided a throughput number (the contrasting I/O gauges are discussed in the cloud-native apps section).
Because small objects will always hit the SSD/NVMe tier there is a danger the hot tier will fill up quickly causing Veeam to wait while the data is periodically drained to the HDDs. For this reason all-flash Objects is a better solution for Veeam, and is the default when the “Backup – Veeam” use case is selected.
Please see the Sizing Nutanix Object for Veeam guidance document.
Special rules for Commvault
If Commvault is the backup app, check whether the customer wishes to use both Commvault’s deduplication and WORM. If this is the case (and it often is), the storage requirement must be increased by 2.4x.
Please see the Sizing Nutanix Object for Commvault guidance document.
Use Case: Archive
Archive is very similar to Backup and so the same advice applies. The profile values aren’t quite the same however, as you can see below. As with Backup though, these can be customized to the customer’s specific workload needs.
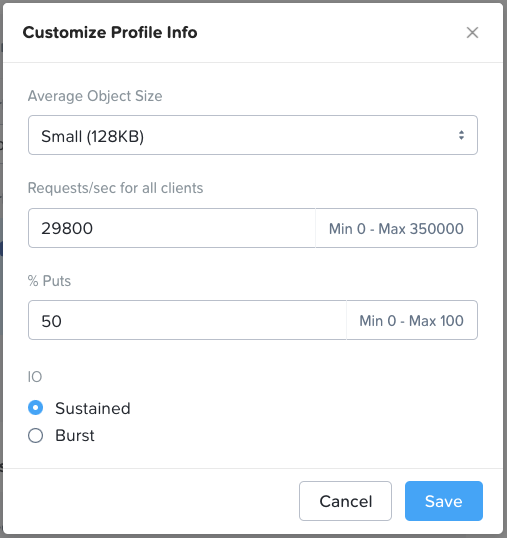
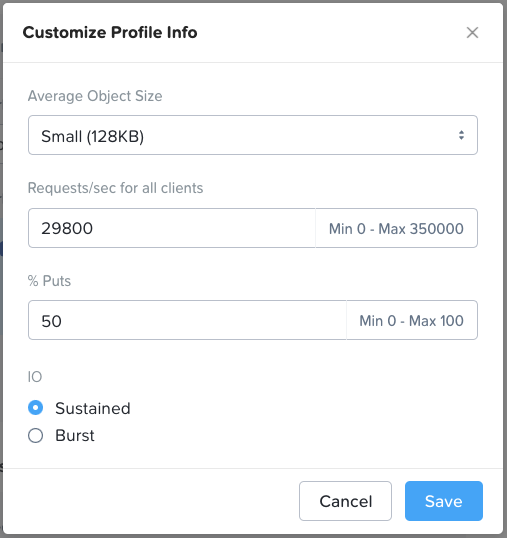
Use Case: Cloud-Native Apps
Cloud-native is a broad category covering a wide range of workload profiles. The correct I/O profile here depends on whether (and how) a containerized application will leverage Objects, or whether Objects is being deployed to support K8s management functions (or both). Object storage is commonly used in a K8s supportive role as an image registry, a log target and/or a backup repository. However, the cloud-native category can also include live application data, including anything from containerized big data/ analytics application data to vector database indexes and logs used in AI inference, all of which have intensive I/O requirements. For this reason, the default profile in Sizer (shown below) reflects a workload that’s performance sensitive in nature. Object size can also vary greatly in this category, but with many cloud-native workloads the object size will be much smaller than with traditional backup and archive workloads, so the profile defaults to a small object size. Smaller objects result in random I/O rather than sequential, and when this is the case all flash nodes are an infinitely better choice than hybrid. Note that this random I/O value is expressed in Sizer in requests/sec, rather than the MB/sec throughput metric that’s used to represent large object sequential I/O. These metrics are consistent with how random and sequential I/O respectively are normally gauged within industry.
When sizing Objects for a cloud-native app it’s important to try and find out from the customer what the I/O profile for the app is, then you can edit the I/O profile settings accordingly. This is especially important given the wide variance of cloud-native workloads types out there. In the absence of such information, all flash is the safe choice.
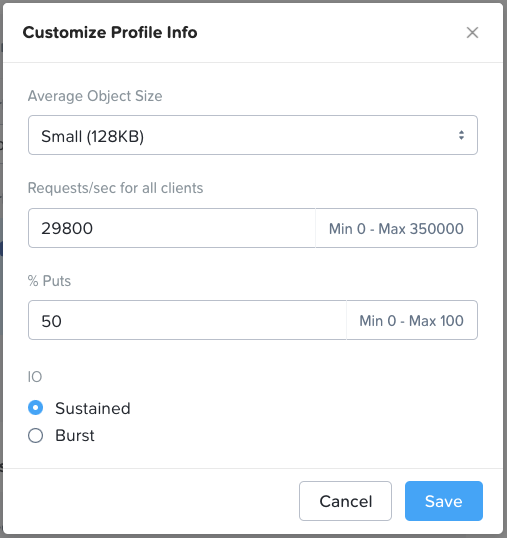
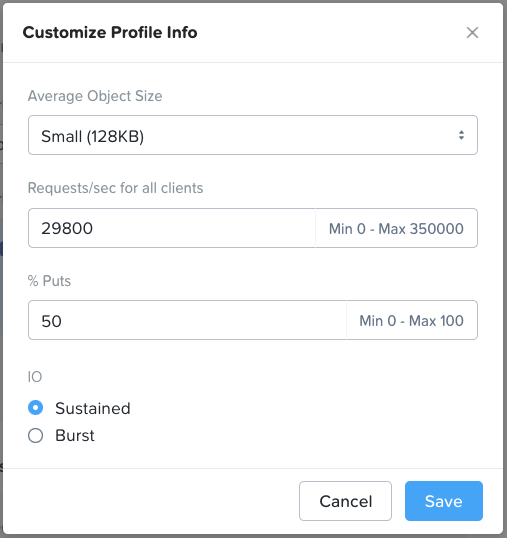
There is also a “Number of Objects (in millions)” field for all workload types. This is often relevant to cloud-native workloads (though not exclusively so), which can result in billions of objects needing to be stored and addressed. This value is used to determine how many Objects workers are needed to address the number of objects that will be stored. Thus, it could be that an Objects cluster sizing is constrained not by performance nor by capacity, but by metadata requirements.
What’s Missing from Sizer Today?
There are some sizing scenarios that are not currently covered by Objects Sizer. These are listed below, together with advice about what to do.
Sizing for intensive list activity
Szier cannot account currently for list activity. However, if you have been given a list requirement that you need to factor into your sizing, note that we have done benchmarking against list activity – the results can be viewed here.
Work with your local NUS SA to extrapolate these benchmarks to your customer’s requirement.
Objects sizes not currently represented in Sizer
Sizer currently only represents 128KB objects (small) and 8MB+ objects (large) – another object size is included (768KB) but it’s specifically for Veeam.
Small and large object workloads have very different performance profiles.
Objects from 8MB and above in size have a consistent performance profile, so select 8MB+ when you need to represent objects greater in size than 8MB, the output will be accurate. In Sizer, object size doesn’t matter above 8MB because you simply enter the overall throughput required (rather than requests/sec), together with the % puts (writes).
However, object sizes from 1KB right up to just under 8MB have logarithmically different performance profiles, meaning it is not easy to predict the performance of (for example) a 768KB object workload given what we know about 128KB performance and 8MB performance. Fortunately engineering has benchmark data for various object sizes other than 128KB and 8MB and this data can be used to identify a configuration that’s a closer fit to your customer’s specific object size. Work with your local NUS SA if you have this requirement. More object sizes will be added to Sizer in the future.
It’s again worth pointing out that objects >1.5MiB in size are classed by AOS as sequential I/O and will go straight to the HDD tier. Objects of 1.5MB or less, on the other hand, are classed as random I/O and will go straight to the SSD/NVMe tier. Knowing your customer’s object size in light of this fact is a significant factor (though not the only one) in helping you understand whether hybrid or all-flash is likely to be the better option.
Veeam and Commvault
These backup apps have additional considerations that can significantly affect the Objects cluster specification. You should not expect a straightforward ‘vanilla’ Backup sizing to be appropriate for these. Veeam is less of a challenge to size given that Sizer has a specialist category for Veeam workloads (“Backup – Veeam”). We are hoping to add a specialist Commvault category to Sizer in the future. In any case, please refer to the below documents when sizing Veeam or Commvault.
Visit the Sizing Nutanix Object for Veeam guidance document for more details.
Visit the Sizing Nutanix Object for Commvault guidance document.
If you have any doubts or difficulties sizing Objects, don’t hesitate to contact your local NUS Solution Architect (SA) for assistance. The SAs are listed here – https://ntnx-intranet–simpplr.vf.force.com/apex/simpplr__app?u=/site/a0xf4000004zeZ7AAI/dashboard
