We launched our second sprint for May and it is a BIG one
Key Enhancements
Super Auto Automatic goes through all the options and finds the optimal sizing. Often SEs will say Auto is a good start but I want play with it. Increase or decrease nodes and see impact of dials. Increase/decrease Cores, RAM, etc and again see that impact.
Well now we have Super Auto where right in where you see the recommendation and the dials you can make those changes and get the update for the dials. Better yet you see % change in cost vs optimal. Manual is still there but now you can do a lot more in Automatic sizing.
Proposals We had the sizer screen shots for a few months now, but we worked with the Field Enablement team and Product Marketing to deliver the latest in corporate overview and product/ solution benefits. Don’t have to hunt around for the latest. Do your work in Sizer and the latest PowerPoint is available under Download Proposals. We see this evolving but you can be assured you got the latest.
Oracle updates Oracle often is used in larger Enterprise applications and they charge for all cores in a node running Oracle. Given that we now require high speed processors (greater than or equal to 60 spec ints which is about 3Ghz) but do allow a VM to cross sockets in a node. This way you can have a large Oracle VM and know it will be fulfilled with a high speed cpu with fewer cores to give you a higher end system and lower Oracle license costs.
Miscellaneous
Heterogeneous cluster support for N+1 in Storage Calculator. We had been taking one node off the first model defined and now we take it off the largest node in the cluster.
Appliances can have addons like Prism Pro, Flow, Calm. This was for decoupled nodes in the past
First sprint for May
Key Enhancements
Backup Sizing. Now all workloads for Nutanix sizings can have backups in a separate backup cluster. You can define the backup policy and target either Files Pro or Buckets Pro. The intent is that the backups are in the backup cluster managed by 3rd party backup software. Sizer sized for the backups, included either Files PRO or Buckets Pro, and allocated space for the backup software. In near future, there will be dedicated Backup hardware that can be used in the backup cluster instead of Files PRO or Buckets Pro. Here is the details
All Nutanix workloads now support backups. This does the following
For any workload you can define backup policy in terms of number of full and incremental backups.
When invoked Sizer computes the backup storage that is needed and puts that in a standalone cluster. Only backup workloads can be included in the backup standalone cluster(s)
Sizer also allocates cores, ram and storage for 3rd party backup software in the backup cluster
In future, you can specify the backup hardware that is to be used in the backup cluster(s).
Alternatively we do offer Files Pro and Buckets Pro standalone clusters as targets
The inputs are as follows
Recovery Point Objective – the time between last backup (be it incremental or full backup). This represents what point in time you can recover data.
For example, you want to recover some information. The last backup will have occurred less than or at most 24 hours ago
Backup cycles. This would be the number of cycles you want retained
Full backups in a cycle. Typically 1 but can be more. Here all the data in the workload is backed up
Incremental backups in a cycle. Typically several and amount of data is the % percent change * workload data
Retention in Days – Backup cycles * (Full Backups per cycle + Incremental backups per cycle)
Rate change – Percent change expected between incremental backups
Backup Target – options for holding the data such as Files Pro
Standalone Cluster – Name of cluster that will hold the backups
Bet you like to see the effect an extra workload has on your sizing.? Betting you do that multiple times when you work with Sizer? Well now you can disable a workload and it is like it has been deleted. Flip the switch and voila it is back.
The use for this feature is tremendous. Certainly to add a workload and see impact. Coupled with ability to clone and edit workload and then could have a couple levels (say small and large). Then toggle each one to be disabled and see the impact the difference in workloads make.
We took care in how we handle disable workloads as follows
o You get a warning on top that one or more workloads are disabled so you don’t forget.
o Since the sizing is based on just enabled workloads the BOM, budgetary quotes and quotes are based on what is enabled
o You can clone the scenario and the current state of enabled/disabled workloads are preserved in the new scenario. So can have multiple scenarios from there with some enabled and other disabled
Capacity growth for Files – this is important as File capacity is always growing and now can size for up to next 5 years
Collector and Tools
Warn you if too few of VMs can’t be sized (eg. Many are powered OFF). This is to inform you that the sizing could be undersized given the data
SpecInt core adjustment for Collector import
Default selections for VDI workloads by Collector Import (Also enable Files by default)
RVTools 3.11 Import support
Miscellaneous
Updated Calm as no longer offers a free 25VM pack
Product updates for NX, SW only vendors, and Dell XC
Validator Product Updates
Failover Capacity Indicator improvements for ECX and Block Awareness enabled scenarios
Oracle: Node allocation to DB VMs
Automatic Sizing with CBL improvements for Standalone cluster sizing
First Sprint released April 16
Key Enhancements
Auto Sizing with CBL – We take into account the CBL license cost in our Auto Sizing which is key as most value is now in the licenses. We also moved to List Price Sizing for NX hardware instead of COGS
Manual Sizing Warnings based on Failover indicators. We leverage the new N+0 warnings in our UI but also BOM, Budgetary quote, Quote
120TB Cold Storage support for 5.11. Models will be coming that support this but we are ready
Two node ROBO sizing for Files for N+1 failover. This is great for lower end file server market
Add Files/Buckets SKUs for quotes for non-decoupled accounts – So now can have a Files or Buckets license with an appliance sale.
ROBO VM Limit changes – PM did update the limits and so now: no limits on cores, 32GB RAM per VM, 2 TiB of combined HDD/SSD storage per VM, and 50 TiB total HDD/SSD storage per cluster
Miscellaneous
Default NIC Selection for ALB/Non-ALB Countries (Auto Sizing). We take care of this nuisance where have to have the right NIC SKU for Arab League and non Arab League countries. We look at the country for the Account you are sizing for.
Oracle Workload only in dedicated clusters. This is best practice given Oracle charges for all cores on nodes with Oracle.
Require an external NIC card for Bucket workloads
New UX Implementation for allowing decoupled quote for non-decoupled accounts – We want to make easier to sell a CBL deal to non-decoupled accounts
Optimal VDI Sizing with Collector- This is huge innovation. We started Collector to get the best customer requirements and now that is reality for our top workload – VDI.
Here you run Collector at the customer’s site and it will collect 7 days of performance data from VCenter. The information is already in VCenter and so it does not take long to grab that information (about 5 min). In Collector you can specify if want to find the median value, average, peak or some percentile like 80% for each VM. For example, 80th percentile means you are getting the cores and RAM utilization level that covers 80% of all the data points from last 7 days. There you can be assured it is well sized as not all VMs will run that hot all the time. That is what I would advise.
With that data going to Sizer we can then “right size” the VM so you don’t undersize or oversize it. All the details are here
https://services.nutanix.com/#/help/articles/532
This is our first workload. I don’t mean this as hype but Collector will radically change sizing and in the process allow Nutanix to be more competitive Why? Because we will have precise customer data to size with.
In compute oriented workloads we will be doing similar processing as we did here for VDI. For capacity workloads, like Buckets or Files we want to analyze data to get us the best compression values. So this is just the sta
Hot storage allocation with FATVM – Here if you have a large working set for Files or buckets we allow the SSD (hot storage) to be dispersed over the cluster. Usually we want it on the local node for best performance (e.g. a heavy compute intensive VM) but here it is not a concern. So net result is you can have a lot of large hybrid models
Allow decoupled quotes on non-decoupled accounts for the partners* – This is allowed now and we got this functionality to partners
Various product updates* across HP, Lenovo, and Nutanix (edited)
First Sprint
Add N+0, N+1, N+2 indicator
o This is a BIG sizing improvement in Sizer where Sizer will always tell you if you are at N+0, N+1 or N+2 for all resources (CPU, RAM, HDD, SSD) for each cluster
o Now as you make changes in manual you always know if you have adequate failover. Best practice is N+1 so you can take down any one node and customer workloads can still run.
o This can be very hard to figure out on your own. ECX savings for example varies by node count. Heterogenous clusters mean you have to find the largest node for each resource. Multiple clusters mean you have to look at each separately. Sizer does this for you !!
o Here is all the info on how this works. https://services.nutanix.com/#/help/articles/512
Allow decoupled quotes on non-decoupled accounts (SFDC Users) – At first the rule was an account had to be decoupled to get decoupled quotes or quotes with Files Pro or Buckets Pro. Now that rule has been lifted and we support that in Sizer quoting. We just ask you if you want de-coupled quotes or not.
ROBO VMs Sizing (Quoting, BOM with ROBO SKUs) – Here can have the new ROBO VMs where you sell VMs as a license and separately have hardware
3 Node sizing for N+1 for Files – This allows a 3 node cluster to be used for Files. Was 4 nodes was the minimum to be N+1
Add missing terms for Appliance Only License and Support
Multiple Clusters Support for Collector Import – Now can put different VMs in different clusters in Sizer
Default NIC Selection for ALB/Non-ALB Countries (Manual Sizing)
Want to add on some cool Essentials products to the HCI offering. It is easy with Sizer
Prism Pro – 1 per node
Flow – 1 per node
Calm – ½ VM pack per node (rounded up)
Files – Capacity is 5TiB per node
It should be a decoupled quote (separate license and hardware). We use the terms and support level for the software license. However, Calm is ONLY Mission Critical level of support
In the right situations, Sizer can be very beneficial for technical customers planning deployments for the following reasons:
Collaborative sale
Customers can scope out new emerging projects and then later pull in SE
Customer confidence and ownership in a proposed solution increases when they are involved in sizing
Build a better bond with SE
Customers can do what-ifs
if add 100 more users how many more nodes needed
If certain application core usage spiked 2x what is the impact on a cluster
Requirements for Success
Customers have to understand Acropolis and the workloads they are sizing. Sizer does have profiles and offers guidance in the wiki, but we assume a knowledgeable user.
SE would need to provide training though there are videos on the wiki
SE would need to be front line support to explain nuances in AOS, workloads, sizing, and Sizer
By default, when customers sign up on MyNutanix, they have access to the “Basic” version of Sizer. The basic access limits the hardware sizing to Nutanix NX hardware.
Process to request access to the Advanced version of Sizer
1. SE requests Sizer PM (sizerhelp@nutanix.com) to bump up the customer level to Sizer advanced
2. SE agrees to be front-end and provide training (to complement videos)
Key things to note
SE has to provide support
We will need to know what vendors the customer can have access to like Nutanix, HPE, Cisco, etc. We can offer almost any combination
Customers will see budgetary list pricing with the Budgetary quote option
Nutanix software pricing is available irrespective of the vendors
Hardware prices are available for Nutanix NX, HPE-DX and AWS Bare Metals
Nutanix and HPE-DX hardware prices are updated monthly and quarterly, respectively.
AWS Bare Metal and EBS Volume prices are fetched on the fly
We had two sprints in February and released the following:
New Features
Changed the Nutanix Files Licenses and now reflect the Jan 2019 changes for Files and Files Pro
Sizer is up to date with the latest licensing including putting Files Pro in a standalone cluster and not allowing Files to be in a standalone cluster. You will see the label standalone cluster in the cluster list. All things are enforced regarding capacity, compression, etc
Nutanix File license now has no maximum capacity
Create scenario proposal
We got feedback from the SE council that SE’s need help in proposals. Often SE’s were taking screenshots of Sizer UI like dials or configuration information. Now a pulldown option to download proposal. A new tab shows all the charts, dials, sizing detail tables. You can download to a powerpoint too. That take the images you want :blush:
Collector Import – Now we note in the the workload if sizing information came from Collector. This is true for the BOM or in View workload
VDI Solution
Allows you to sell a VDI solution based on user pricing. Customer pays for so many users independent of the workload demands they have. Separately is the hardware cluster which is sized to meet the workload demands
By selecting Enterprise VDI Solution when creating a VDI workload that workload is put into a standalone cluster and then the only VDI license is charged. Separately the hardware is sized for that workload and potentially other Enterprise VDI Solution workloads
Buckets Licensing – Licensing is now implemented to include rules for Nutanix Buckets and Nutanix Buckets Pro
Nutanix File Pro Encryption and Nutanix Buckets Pro Encryption has been added as option in those workloads
Intel models available to NX partners. Initially for just Nutanix employees, but not Nutanix partners too.
Product Updates:
HCL Product updates for SW only vendors
XF1070 – Fujitsu – product updates
Lenovo Product updates: New model: HX2320 & added 16G DIMM for HX7820
Nutanix G6 Product Constraint – GPU_4PORT_NIC_limit was added
This is a BIG sizing improvement in Sizer where Sizer will always tell you if you are at N+0, N+1 or N+2 failover level for all resources (CPU, RAM, HDD, SSD) for each cluster.
Now as you make changes in automatic sizing or manual sizing you always know if you have adequate failover. Best practice is N+1 so you can take down any one node (e..g take one node offline for an upgrade) and customer workloads can still run.
This can be very hard to figure out on your own. ECX savings for example varies by node count. Heterogenous clusters mean you have to find the largest node for each resource. Multiple clusters mean you have to look at each separately. Sizer does this for you !!
Here is what you need to know.
Let’s take a two cluster scenario. One called Cluster-1 is Nutanix cluster running 900 users for VDI and the Files to support those users. The other is a standalone cluster for Files Pro with 100TB of user data
All clusters:
In a multi-cluster scenario All Clusters just provides a summary. Here it shows two clusters and the hardware for the clusters. In regards to N+1 indicator on the lower left it shows the worse cluster. Both are N+1 and so you see N+1. Had any cluster been N+0 then N+0 would be shown. Great indicator to show there is an issue with one of the clusters
File cluster
This is the Standalone cluster for Files. You see the hardware used in the cluster. You see the failover level for each resource (CPU, RAM, HDD, SSD). N+2 would indicate possibly could have less of that resource but often product options force more anyhow. This is cold storage intensive workload and so HDD is the worse case.
Cluster -1
This is the Nutanix cluster for the VDI users. You see the hardware used in the cluster. You see the failover level for each resource (CPU, RAM, HDD, SSD). This is core intensive workload and so that is the worse case.
In the past object storage solutions were only concerned with capacity; performance was barely a consideration. However, modern workloads such as AI/ML and data analytics leverage S3 compatible storage, and these very often have significant performance demands. Nutanix Objects has been internally benchmarked with both hybrid and all flash systems (see https://portal.nutanix.com/page/documents/solutions/details?targetId=TN-2098-Nutanix-Objects-Performance-INTERNAL-ONLY:TN-2098-Nutanix-Objects-Performance-INTERNAL-ONLY) and as a result we have a good understanding into Objects’ performance capabilities with a variety of workload profiles. Extrapolations can reliably be taken from these results to model performance scaling, since Objects I/O performance scales linearly. Importantly, the empirical data gleaned from the benchmark testing is leveraged by Sizer to determine the minimum number of Objects workers – and therefore nodes (Objects enforces 1 worker per node per object store for HA reasons) – needed to deliver a certain level of performance.
It should also be noted that there are factors outside the object store, such as network speed and number of client connections, that play a significant role in achieving the best possible performance from Nutanix Objects. Regarding the number of client connections, it should be noted that each node/worker needs 60-75 concurrent client connections driving I/O for maximum performance potential to be realized.
More commonly, node count will be driven by capacity requirements. Even in these cases however, the minimum Objects worker count needed for the required performance should still be noted, especially in mixed deployments (discussed further below).
Configurations
While there is no difference in NUS licensing between dedicated deployments (the AOS cluster is dedicated to NUS) and mixed deployments (NUS resides on the same cluster as application VMs), sizing considerations in each scenario vary to a degree. These are discussed below.
Worker count and HDD spindle count (or SSD count if All Flash)
In scenarios where a certain level of performance must be met, Sizer will look at the number of workers needed and the number of HDDs (or SSDs in the case of all flash) needed to deliver the throughput entered*. A high performance worker on an all flash node can, in most scenarios, deliver substantially more throughput than a standard worker on a hybrid node.
Disk-wise, in RF2 configs Sizer assumes a single SATA HDD can deliver reads:100MB/s and writes:50MB/s. Sizer assumes a single SSD can deliver reads:500MB/s and writes:250MB/s. So for example, a hybrid node with 10*HDDs can deliver 1GB/s for a workload consisting entirely of reads, or 500MB/s for a workload consisting entirely of writes. If RF3 or FT1n/2d is selected the write throughput figure is increased by 50% to account for the additional disk write IO. Note that FT1n/2d is strongly recommended for storage dense configs.
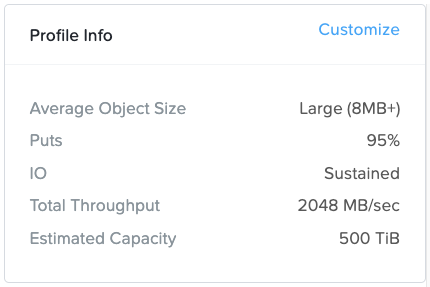
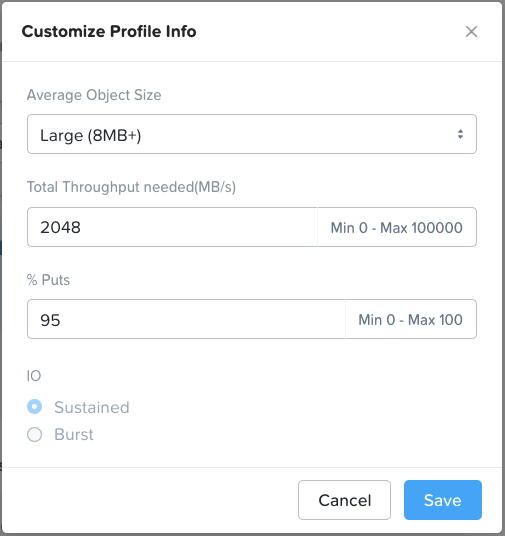
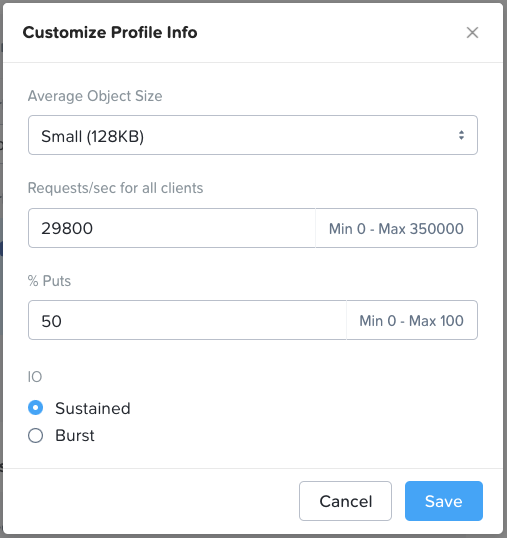
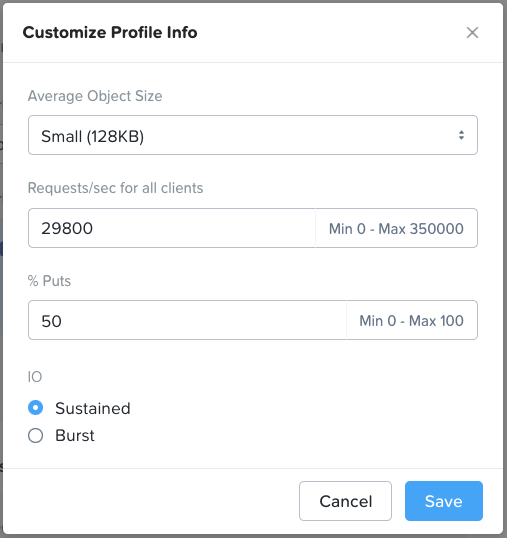
*For performance sensitive sizings please do not just accept the default values in the performance profile section (“Profile Info” box in the top right of the Workload page). The default values are purely arbitrary. You must determine the actual average object size, R/W (get/put) split and throughput that the customer needs to achieve and enter that customer-specific data into the Profile Info section.
For an Objects dedicated configuration (hybrid)
Objects is supported on all models and platforms that can run AOS (NCI). However, if you’re sizing for a dedicated hybrid Objects cluster with 100TiB or above, we recommend the HPE DX4120-G11, NX-8155-G9 or equivalent for the best performance. Such models are ideal due to their high HDD spindle count (as discussed in the previous section), though any model will work as long as it matches the minimum configurations listed below.
CPU: dual-socket 12-core CPU (minimum) for hybrid configs with 4 or more HDDs
Dual-socket 10-core CPU is acceptable for hybrid configs in use cases that do not require fast performance
Memory: 128GB per node (minimum)
Disk:
Avoid hybrid configurations that have only 2 HDDs per node.
For hybrid configurations that need to deliver good throughput, systems with 10+ HDDs are highly recommended. On an NX8155 for example go for 2*SSD + 10*HDD rather than 4*SSD + 8*HDD. This is further explained in the below section Why 10+ HDDs in a dedicated hybrid config?
If a system with 10 or more HDDs is not available, configure the system with the highest number of HDDs possible.
Erasure Coding: inline enabled (set by default during deployment)
Note inline EC has a 10-15% impact on write performance (accounted for if you choose “inline EC” in Sizer)
FT choice: choosing between RF3, FT1N/2D and RF3 has an impact on the system’s deliverable write throughput (see previous section “Worker count and HDD spindle count (or SSD count if All Flash)”)
Network: dual 25GbE generally recommended (but check calculation in “Network” section)
NOTE: In Sizer to force a hybrid cluster output make sure “Hybrid” is selected under “Worker Node”. Sizer does not automatically choose between hybrid or all-flash for you.
Licensing: NUS Starter covers any Objects deployment on a hybrid system (whether shared or dedicated).
Why 10+ HDDs in a dedicated hybrid config?
In the majority of today’s use cases objects tend to be large (>1.5MiB), meaning they manifest as sequential I/O on the Nutanix cluster. In response to this, Objects architecture is tuned to take full advantage of the HDD tier. If there are HDDs in a node, Objects will automatically write sequential data directly to them, while leveraging the SSDs purely for metadata (if there are any objects under 1.5MB these will land in the SSD tier).
There are 3 reasons for this;
Solid sequential I/O performance can be achieved with HDDs, assuming there are enough of them
Objects deployments can be up to petabytes in size. At that sort of scale, cache or SSD hits are unlikely, so using SSDs in hopes of achieving accelerated performance through caching would provide little return on the additional costs. To keep the solution cost-effective, Objects minimizes SSD requirements by using SSDs for metadata, and only using for data if required.
Since we recommend a dual-socket 12-core CPU configuration, fewer SSDs also helps to avoid system work that would otherwise be incurred by having to frequently move data between tiers – the result is less stress on the reduced CPU count.
If, however, the workload is made up of mostly small objects, all-flash systems are significantly better at catering for the resulting random I/O, particularly if the workload is performance intensive.
For an Objects dedicated configuration (all-flash)
If all-flash is the preference, any system with 3 or more SSD/NVMe devices is generally fine, although the calculation described earlier must be performed based on actual throughput requirements (Sizer does this). If the all-flash nodes must also be storage dense we recommend the NX-8150-G9. From a compute standpoint, all-flash Objects clusters should have a minimum of:
CPU: dual-socket 20-core CPU (minimum) for all-flash configs – importantly, this allows the “Performance Config” to be selected at deployment
Memory: 128GB per node (minimum)
Disk: For all flash configurations, systems with 3 SSDs/NVMes (or more) are recommended.
Erasure Coding: inline enabled (set by default during deployment)
Note inline EC has a 10-15% impact on write performance (accounted for if you choose “inline EC” in Sizer)
FT choice: choosing between RF3, FT1N/2D and RF3 has an impact on the system’s deliverable write throughput (see previous section “Worker count and HDD spindle count (or SSD count if All Flash)”)
Network: quad 25GbE, dual 40GbE or higher generally recommended, and for very high performance requirements dual 100GbE will be needed (check calculation in “Network” section)
NOTE: In Sizer to force an all-flash cluster output make sure “All Flash” is selected under “Worker Node”. Sizer does not automatically choose between hybrid or all-flash for you.
Licensing: NUS Pro covers any Objects deployment on an all flash system (whether shared or dedicated).
For a mixed configuration (Objects coexisting with User VMs)
Objects is supported on any model and any platform as long as it matches the minimum configurations listed below.
CPU: at least 12 vCPUs are available per node
All node types with dual-socket CPUs are supported and preferred, though single CPUs with at least 24 cores are also supported
Memory: at least 36GB available to Objects per node
Disk: avoid hybrid configurations with only 2 HDDs per node and bear in mind that more HDD spindles means better performance.
Erasure Coding: Inline enabled (set by default during deployment)
Note inline EC has a 10-15% impact on write performance (accounted for if you choose “inline EC” in Sizer)
FT choice: choosing between RF3, FT1N/2D and RF3 has an impact on the system’s deliverable write throughput (see previous section “Worker count and HDD spindle count (or SSD count if All Flash)”)
Network: dual 25GbE recommended (but check calculation in “Network” section)
Both the NUS Starter and Pro licenses allow one User VM (UVM) per node. If taking advantage of this, ensure that there are enough CPU cores and memory on each node to cater for both an Objects worker and the UVM – and potentially also a Prism Central (PC) VM, unless PC will be located on a different cluster. It’s important to understand that Nutanix Objects cannot be deployed without there being a Prism Central present somewhere in the environment.
Network
This section provides information on working out the network bandwidth (NIC speed and quantity) needed per node, given the customer’s throughput requirement and the number of load balancers in the deployment. Conversely, it can be used to work out how many load balancers are needed, particularly if the customer is limited to a particular speed of network. At the end of this section is a link to a spreadsheet that helps you perform these calculations.
Note that Sizer does not perform these calculations. Sizer will statically configure all-flash Object nodes with 4 x 25GbE ports (two dual port cards). However, that might not be enough so it’s important that you do the performance calculations below and, if necessary, manually increase the NIC speed and/or quantity in Sizer as needed.
1. Firstly it’s important to be aware that for each put (write) request received by Objects there is 4x network amplification. The write path is as follows:
Client > Load Balancer (1) > Worker (2) > CVM (3) > RF write to another CVM (4)
If RF3 or 1N2D is selected this increases to 5x network amplification
For each get (read) request received there is 3x amplification. The read path is as follows:
CVM > Worker (1) > Load Balancer (2) > Client (3)
If EC is selected (EC is default if there are enough nodes) read amplification could, for many gets, increase to 4x if parts of the EC strip need to be read from other CVMs.
So the total network bandwidth needed for the object store is determined by the customer’s requested throughput multiplied by these factors in the correct proportions (R/W). The resulting overall bandwidth requirement is then spread across the load balancers – a relatively even distribution is assumed.
2. Take whatever % of the customer’s throughput is write IO (puts) – this is typically expressed in MB/s or GB/s – and multiply by 4 (or 5 – see above) to account for the write amplification. Next, take whatever % of the customer’s throughput is read IO (gets) and multiply that by 3 (or 4 – see above) to account for the read amplification. Combine the results and you have the overall throughput requirement to/from the cluster.
Total bandwidth to/from object store = 4 GB/s + 12 GB/s = 16 GB/s
3. Divide the overall throughput figure by the number of load balancers you plan to deploy. The result is the amount of network bandwidth needed per physical node.
Example:
4 Load Balancers
16 GB/s / 4 = 4 GB/s per node
4. Map this figure to the real world limits of NICs of varying speeds. These are listed below for your convenience. Note that when 2 links are aggregated using LACP you do not get twice the bandwidth of a single link due to overheads. With 2 links in LACP you can assume ~20% bandwidth loss, with 4 you can assume ~40% loss. Further to that, and before LACP overhead is accounted for, a NIC’s advertised bandwidth is never fully achievable due to general networking overheads (protocol and other real world factors).
# links in LACP
1 (no aggregation)
2
4
Achievable GB/s
1.1
1.8
2.7
Usable bandwidth with 10GbE
# links in LACP
1 (no aggregation)
2
4
Achievable GB/s
2.8
4.4
6.6
Usable bandwidth with 25GbE
# links in LACP
1 (no aggregation)
2
4
Achievable GB/s
4.4
7.0
10.4
Usable bandwidth with 40GbE
# links in LACP
1 (no aggregation)
2
4
Achievable GB/s
10.5
*12.5 (not 16.8)
*12.5 (not 25.2)
Usable bandwidth with 100GbE
*At the time of writing OVS, the virtual switch architecture used by AHV/KVM, has a limit of 100Gbps – this means the maximum network throughput a single node can handle is 12.5 GB/s (100/8). The configurations affected by this are 2x and 4x 100GbE links in LACP. There are future plans to lift this limit (roadmap item).
Example:
4 GB/s per node is needed.
Each node needs 2 x 25GbE NICs (in LACP), which can do 4.4GB/s
This spreadsheet may help with the network bandwidth and load balancer calculations.
Sizing Use Cases
Use Case: Backup
Below is a Backup workload in Objects Sizer. In this scenario Nutanix Objects is used as a target to store backups sent from backup clients (i.e. the backup app).
Note that Nutanix Objects should not be located on the same physical cluster as the source data (i.e. the data being backed up).
Considerations when sizing a backup workload
Initial capacity – estimated initial capacity that will be consumed by backups stored on Nutanix Objects.
Capacity growth – % growth of the backup data per time unit (e.g. years) over an overall specified length of time.
Be cautious and do not attempt to cater for too long a growth period, otherwise the amount of capacity required due to growth could dwarf the amount of storage required on day one. Specifying a (for example) 10-year growth period undermines our fundamental pay-as-you-grow value. Plus of course growth predictions may not be entirely accurate in any case. 3 years is a typical growth period to size for.
Do not enable Nutanix deduplication on any Objects workloads.
Profile Info:
All values can be customized as required.
Write (PUT) traffic usually dominates these environments as backups occur more regularly than restores (GETs). Furthermore, when restores do occur they are usually just reading a small subset of the backup.
That said, more and more customers are becoming increasingly concerned with how fast all their data could be restored in the event of a ransomware attack – so do check this with the customer
Backups usually result in sequential I/O so the requirement is expressed as MB/s throughput. Veeam is the one exception to this rule – discussed further below.
Backups usually consist of large objects (with the exception of Veeam – discussed further below)
“Sustained” only applies to small object (<1.5MB) puts. In a hybrid system, when the hot tier fills up the application I/O must wait while the data is drained from SSD/NVMe to HDD. This is why sustained small object put throughput is slower than burst small object put throughput.
Replication Factor
When using nodes with large disks (12TB+) to achieve high storage density it’s recommended you use RF3 or, better still, 1N/2D if there are 100 or more disks in a single fault domain. This provides a higher level of resilience against disk failure. Disk failure is more likely in this scenario for two reasons:
The more disk hardware you have the greater the risk of a disk failure
Disks take longer to rebuild because they contain more data, thus the window of vulnerability is extended (to days rather than hours)
The larger drive capacities also mean there is a greater chance of encountering a latent sector error (LSE) during rebuild
This drives a real need for protection against dual disk failure – true regardless of whether the disks are HDD or SSD/NVMe.
1N/2D coupled with wider EC strip sizes is preferred to RF3 due to it being more storage efficient
If you wish to stick with RF2, consider using multiple Objects clusters.
However each cluster will have its own N+1 overhead.
Special rules for Veeam
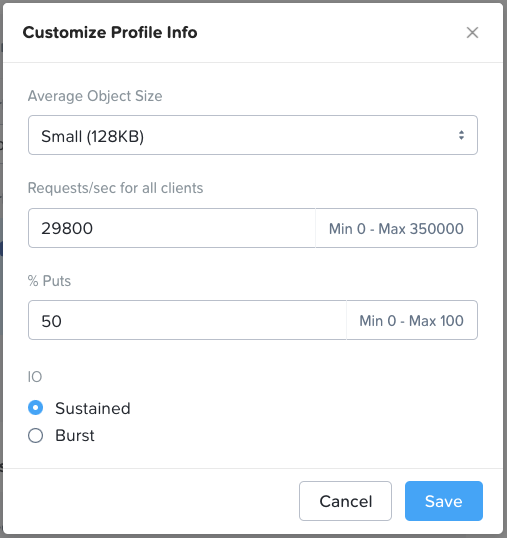
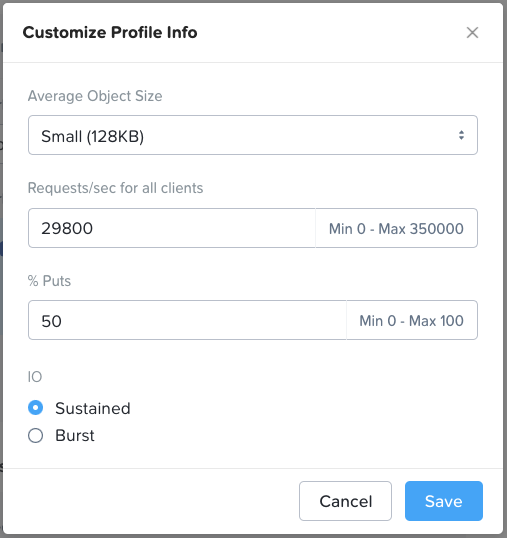
Veeam is different from other backup apps in that it does not write large objects. With Veeam the default object size is ~768KB, about a tenth (or less) of the size of objects generated by other backup apps. Therefore, for Veeam opportunities the specialized “Backup – Veeam” use case in Sizer should be selected. Note that small object performance requirements must be expressed in Sizer in requests/sec rather than MB/sec. Therefore some conversion may be required if the customer has provided a throughput number (the contrasting I/O gauges are discussed in the cloud-native apps section).
Because small objects will always hit the SSD/NVMe tier there is a danger the hot tier will fill up quickly causing Veeam to wait while the data is periodically drained to the HDDs. For this reason all-flash Objects is a better solution for Veeam, and is the default when the “Backup – Veeam” use case is selected.
If Commvault is the backup app, check whether the customer wishes to use both Commvault’s deduplication and WORM. If this is the case (and it often is), the storage requirement must be increased by 2.4x.
Archive is very similar to Backup and so the same advice applies. The profile values aren’t quite the same however, as you can see below. As with Backup though, these can be customized to the customer’s specific workload needs.
Use Case: Cloud-Native Apps
Cloud-native is a broad category covering a wide range of workload profiles. The correct I/O profile here depends on whether (and how) a containerized application will leverage Objects, or whether Objects is being deployed to support K8s management functions (or both). Object storage is commonly used in a K8s supportive role as an image registry, a log target and/or a backup repository. However, the cloud-native category can also include live application data, including anything from containerized big data/ analytics application data to vector database indexes and logs used in AI inference, all of which have intensive I/O requirements. For this reason, the default profile in Sizer (shown below) reflects a workload that’s performance sensitive in nature. Object size can also vary greatly in this category, but with many cloud-native workloads the object size will be much smaller than with traditional backup and archive workloads, so the profile defaults to a small object size. Smaller objects result in random I/O rather than sequential, and when this is the case all flash nodes are an infinitely better choice than hybrid. Note that this random I/O value is expressed in Sizer in requests/sec, rather than the MB/sec throughput metric that’s used to represent large object sequential I/O. These metrics are consistent with how random and sequential I/O respectively are normally gauged within industry.
When sizing Objects for a cloud-native app it’s important to try and find out from the customer what the I/O profile for the app is, then you can edit the I/O profile settings accordingly. This is especially important given the wide variance of cloud-native workloads types out there. In the absence of such information, all flash is the safe choice.
There is also a “Number of Objects (in millions)” field for all workload types. This is often relevant to cloud-native workloads (though not exclusively so), which can result in billions of objects needing to be stored and addressed. This value is used to determine how many Objects workers are needed to address the number of objects that will be stored. Thus, it could be that an Objects cluster sizing is constrained not by performance nor by capacity, but by metadata requirements.
What’s Missing from Sizer Today?
There are some sizing scenarios that are not currently covered by Objects Sizer. These are listed below, together with advice about what to do.
Sizing for intensive list activity
Szier cannot account currently for list activity. However, if you have been given a list requirement that you need to factor into your sizing, note that we have done benchmarking against list activity – the results can be viewed here.
Work with your local NUS SA to extrapolate these benchmarks to your customer’s requirement.
Objects sizes not currently represented in Sizer
Sizer currently only represents 128KB objects (small) and 8MB+ objects (large) – another object size is included (768KB) but it’s specifically for Veeam.
Small and large object workloads have very different performance profiles.
Objects from 8MB and above in size have a consistent performance profile, so select 8MB+ when you need to represent objects greater in size than 8MB, the output will be accurate. In Sizer, object size doesn’t matter above 8MB because you simply enter the overall throughput required (rather than requests/sec), together with the % puts (writes).
However, object sizes from 1KB right up to just under 8MB have logarithmically different performance profiles, meaning it is not easy to predict the performance of (for example) a 768KB object workload given what we know about 128KB performance and 8MB performance. Fortunately engineering has benchmark data for various object sizes other than 128KB and 8MB and this data can be used to identify a configuration that’s a closer fit to your customer’s specific object size. Work with your local NUS SA if you have this requirement. More object sizes will be added to Sizer in the future.
It’s again worth pointing out that objects >1.5MiB in size are classed by AOS as sequential I/O and will go straight to the HDD tier. Objects of 1.5MB or less, on the other hand, are classed as random I/O and will go straight to the SSD/NVMe tier. Knowing your customer’s object size in light of this fact is a significant factor (though not the only one) in helping you understand whether hybrid or all-flash is likely to be the better option.
Veeam and Commvault
These backup apps have additional considerations that can significantly affect the Objects cluster specification. You should not expect a straightforward ‘vanilla’ Backup sizing to be appropriate for these. Veeam is less of a challenge to size given that Sizer has a specialist category for Veeam workloads (“Backup – Veeam”). We are hoping to add a specialist Commvault category to Sizer in the future. In any case, please refer to the below documents when sizing Veeam or Commvault.